We overviewed the current technological and economical trends in high-performance scientific computing. At least for certain range of problems, a special-purpose computer, or, a combination of special- and general-purpose computers such as our GRAPE systems, offer a real and proven advantage over traditional general-purpose computers. The relative advantage has been increasing, and will keep to do so for the next one or two decades. Our GRAPE-6 system will be completed by next year, with the peak speed of 120 Tflops for the total budget of 4.5 M USD. These numbers could be compared with the price and performance of the newest ASCI machine, the Option White, which will deliver around 10 Tflops for the price of around 100 M USD by the end of the year 2000.
In the following, we speculate on the future of large-scale high-performance computing. As we have seen in section 2, the direction of the evolution of ``general-purpose'' parallel computers is such that the application range will be more and more limited, and yet the efficiency of the hardware will go down.
On the other hand, special-purpose systems, at least in principle, will not suffer these problems. In practice, however, the approaches we have taken so far is becoming more and more difficult, because the initial development cost of the custom LSI goes up as the technology advances. The development cost goes up because of two reasons. The first is that the amount of work to do the logic design, test design, physical layout and design validation increases as the number of transistors in a chip increases. In the case of special-purpose systems, the amount of work for the logic and test design, which we can do in-house, does not increase too rapidly, but physical layout and design validation, which is the work of the semiconductor company, take a long time and therefore lots of money. The second reason is that the investment needed to build the semiconductor plant increases rapidly as the technology advances.
Very roughly speaking, for
same physical size of the chip, the amount of money we paid was
inversely proportional to the design rule: around a quarter million
USD for 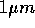 (GRAPE-4) and around 1 million USD for
(GRAPE-4) and around 1 million USD for
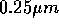 (GRAPE-6). In both case, the size of the chip is
around
(GRAPE-6). In both case, the size of the chip is
around 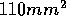 . If this trend continues, the design cost of
. If this trend continues, the design cost of
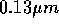 would be two million USD. The total budget must be
significantly larger than the development cost of the chip, since
otherwise the price per performance will be too high. It is not easy
to get such a large fund for a project of theoretical study in pure
science.
would be two million USD. The total budget must be
significantly larger than the development cost of the chip, since
otherwise the price per performance will be too high. It is not easy
to get such a large fund for a project of theoretical study in pure
science.
One possible compromise is the use of FPGA (Field programmable gate array) chips as the building block of the pipelined processors. This choice will reduce the initial cost from one million dollars to less than ten thousand dollars (the price of the design software), since the FPGA chip itself is mass-produced and the design is loaded to a FPGA chip by configuring the switches and lookup tables in the chip.
Roughly speaking, because of this programmability, the calculation speed achieved by one FPGA chip is 100 times lower than that can be achieved with a custom LSI of the same size and same technology. However, this difference can be offset by the possibility of using the most advanced technology, the possibility to fine-tune the design to individual problems, and most importantly, much shorter design cycle time.
To give an example, large FPGA chips at the time of writing (Summer 2000) have the nominal gate count of around half million, which is sufficient to implement the logic for a GRAPE-4 chip (100K gates), and the clock speed would be around 50 MHz or more. Thus, one FPGA chip can deliver 1 Gflops. This might not sound very impressive compared to 40 Gflops of GRAPE-6 chip or around 1 Gflops of present microprocessors. However, compared to microprocessors, to build a massively parallel machine out of FPGA is much easier, and we can expect higher execution efficiency, for the same reason as we achieved higher efficiency on GRAPE hardwares.
Here again, in the long run we might see the same problem as the general purpose computer. The on-chip wiring would ultimately limit the speed and the circuit density. Because of the requirement of the programmability, as the number of transistors on the FPGA chips increases, more and more fraction of these chips will be used for wiring. However, for the next several years, this limitation would not be too severe, and it is possible that some new design philosophy will allow us to make better use of FPGA chips.
It is at least possible to use FPGAs for ``proof of the concept'' studies, where we demonstrate that one particular custom design is actually usable and that it achieves better cost-performance than general-purpose solutions. If that demonstration was successful, the grant large enough to make custom LSI might be offered.
To summarize, the initial cost of the large custom LSI might become too high for the level of the amount of grants we can reasonably expect. However, machines based on FPGAs can be used for small projects. The cost advantage of FPGAs will not be as large as that of custom LSI chips, but compared to general-purpose microprocessors, they still offer large advantage. So we expect to see many successful projects to apply FPGAs for large-scale computing in the near future. The largest ones will be done on custom LSIs, but the rest will be done on FPGAs.