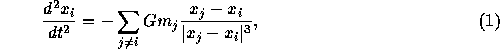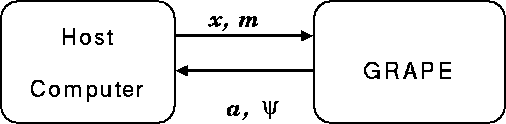In principle, the direct N-body simulation of stellar systems is very simple and straightforward. The only thing one has to do is to numerically integrate the following system of equations of motion:
where 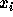 and
and 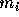 are the position and mass of the particle with
index i and G is the gravitational constant. The summation is
taken over all stars in the system. Unless the total number of stars
in the system is very small, the calculation and summation of the
gravitational forces dominates the total calculation cost.
are the position and mass of the particle with
index i and G is the gravitational constant. The summation is
taken over all stars in the system. Unless the total number of stars
in the system is very small, the calculation and summation of the
gravitational forces dominates the total calculation cost.
We have developed a series of special-purpose computers for N-body simulations, which we call GRAPE (GRAvity PipE). Figure 1 gives the basic idea. The host computer, which is usually a general-purpose workstation running UNIX, sends the positions and masses of particles to the GRAPE hardware. Then GRAPE hardware calculates the interaction between particles. What GRAPE hardware calculates is the right hand side of equation (1). When we use the Hermite scheme (Makino [Mak91]), the first time derivative of the force must also be calculated. Figure 2 shows the block diagram of the pipeline unit to calculate the force and its time derivative.
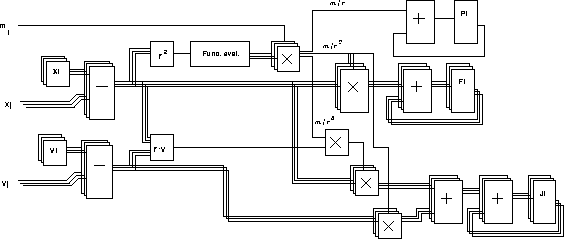
Figure 2: Pipelined processor for the calculation of force and its time
derivative. Reproduced from Makino et al. 1997 [MTES97]).
In order to combine the individual timestep scheme with GRAPE
hardware, one modification of the basic architecture is
necessary. Figure 3 shows the change. In the
individual timestep scheme, particles has their own times and
timesteps. Thus, to calculate the force on a particles i at its own
time 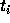 , we need the positions and velocities of all other
particles at time
, we need the positions and velocities of all other
particles at time 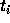 . However, other particles have their own
times, which are generally different from
. However, other particles have their own
times, which are generally different from 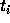 . In the individual
timestep scheme, we use the predictor based on the polynomial
extrapolation to obtain the positions and velocities of other
particles. Each particle has, in addition to position and velocity at
its own time, acceleration and its time derivative, so that we can
construct a third-order predictor. This third-order predictor allows us
to use the fourth-order time integration scheme, either two-step
Hermite scheme or four-step variable-stepsize Adams-Moulton scheme for
second-order equations.
. In the individual
timestep scheme, we use the predictor based on the polynomial
extrapolation to obtain the positions and velocities of other
particles. Each particle has, in addition to position and velocity at
its own time, acceleration and its time derivative, so that we can
construct a third-order predictor. This third-order predictor allows us
to use the fourth-order time integration scheme, either two-step
Hermite scheme or four-step variable-stepsize Adams-Moulton scheme for
second-order equations.
This prediction must also be done on the GRAPE hardware, since otherwise the amount of the calculation the host computer has to do becomes comparable to that of GRAPE, and therefore the speedup will be too limited.
In the original individual timestep algorithm, each particle choses its
timestep freely, based on some timestep criterion. Thus, timesteps and
times of different particles are all different, and time integration
proceeds in an ``event-driven'' manner, where one particle with
minimum 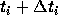 is integrated. This scheme has one obvious
problem that the degree of the parallelism in force calculation is
limited to N, since we can calculate the force on only one
particle. We can force several particles to share exactly the same
time, by forcing their timesteps to be powers of
two[McM86]. This modified individual timestep scheme is
often called the blockstep scheme. This scheme is useful both on GRAPE
and general-purpose computers.
is integrated. This scheme has one obvious
problem that the degree of the parallelism in force calculation is
limited to N, since we can calculate the force on only one
particle. We can force several particles to share exactly the same
time, by forcing their timesteps to be powers of
two[McM86]. This modified individual timestep scheme is
often called the blockstep scheme. This scheme is useful both on GRAPE
and general-purpose computers.
In the modified architecture shown in figure 3, the particle memory keeps all data necessary for prediction, for all particles in the system. At each timestep, the host computer sends the position and velocity of particles to be updated to GRAPE, and GRAPE calculates the forces on them and sends the results back to the host. If the number of pipelines is smaller than the number of particles in the block, this step is repeated until the forces on all particles in the block are obtained. Then the host performs the orbit integration using these calculated forces, and updates the data of the integrated particles in the particle memory of the GRAPE hardware.
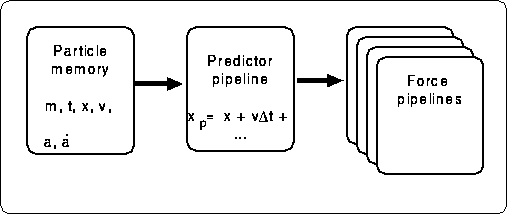
Figure 3: GRAPE for individual timestep
In 1989, we started the development of GRAPE systems. The first hardware, GRAPE-1, [IMES90] was a single-pipeline system with low-accuracy force calculation (r.m.s relative accuracy of 2%), without the predictor hardware. The force calculation pipeline was implemented using integer adder/subtracter IC chips and ROM chips (for lookup tables). It was the proof-of-the-concept machine to demonstrate that theoretical astrophysists (we) could construct a real hardware. It had the peak speed of 240 Mflops, and turned out to be useful for a wide range of astrophysical problems where high accuracy is not very important.
GRAPE-2 [IEMS91] is again a single-pipeline system, but with high accuracy. The pipeline was implemented using commercial floating-point ALU chips such as TI 8847. It had the peak speed of 40 Mflops. For this machine, we did not include the predictor hardware, since with the blockstep scheme it was possible to perform prediction operations on the host computer without significant loss of the efficiency. Of course, this is simply because GRAPE-2 was not so fast.
GRAPE-3[OME 93] is our first multiple-pipeline system, where
low-accuracy force calculation pipeline similar to that of GRAPE-1 was
integrated into a custom chip. The GRAPE-3 chip was fabricated in
93] is our first multiple-pipeline system, where
low-accuracy force calculation pipeline similar to that of GRAPE-1 was
integrated into a custom chip. The GRAPE-3 chip was fabricated in
 rule and had about 100K transistors. The die size was
9mm by 9mm. It has single pipeline unit with operating clock frequency
of 10 MHz, resulting in the speed of 380 Mflops/chip. The full GRAPE-3
system consisted of two boards with 24 chips each, for the aggregated
peak speed of 18 Gflops. A smaller version of this machine, GRAPE-3A,
which has 8 GRAPE-3 chips with the clock speed of 20 MHz, has been
commercially available since 1993 and more than 100 GRAPE-3A boards
have been manufactured and are used by a number of researchers
worldwide.
rule and had about 100K transistors. The die size was
9mm by 9mm. It has single pipeline unit with operating clock frequency
of 10 MHz, resulting in the speed of 380 Mflops/chip. The full GRAPE-3
system consisted of two boards with 24 chips each, for the aggregated
peak speed of 18 Gflops. A smaller version of this machine, GRAPE-3A,
which has 8 GRAPE-3 chips with the clock speed of 20 MHz, has been
commercially available since 1993 and more than 100 GRAPE-3A boards
have been manufactured and are used by a number of researchers
worldwide.
GRAPE-4 (Makino et al. [MTES97]) is the first GRAPE hardware to implement the full predictor hardware with high accuracy. In GRAPE-4, one processor board houses one predictor units and 96 (virtual) force calculation pipelines. The total system in the maximum configuration consisted of 36 boards organized into four clusters, and different boards calculated the forces on the same set of 96 particles. In this way, we met the requirement that the number of forces calculated in parallel is small, even though the number of pipelines is large.
Summation of 9 forces from processor boards in the same cluster is taken care by the communication hardware, and final summation of the forces from four clusters is handled by the host.
A board houses 48 force calculation pipeline chips (GRAPE-4 chips)and one predictor pipeline chip (PROMETHEUS chip). GRAPE-4 chip can calculates one interaction in every three clock cycles, since it processes x, y, and z components in three consecutive clock cycles. It actually calculates the forces on two different particles, using six clock cycles. As a result, a GRAPE-4 chip logically looks like containing two pipelines operating at the clock frequency half of the actual one. We named this feature Virtual Multiple Pipeline (VMP). With VMP, we can reduce the memory bandwidth without sacrificing the performance.
GRAPE-4 was completed in 1995, and has been used by many researchers for the study of many astrophysical problems[HM99,MT98].
Figure 4 shows the peak speed of our GRAPE systems and that of representative high-performance general-purpose computers.
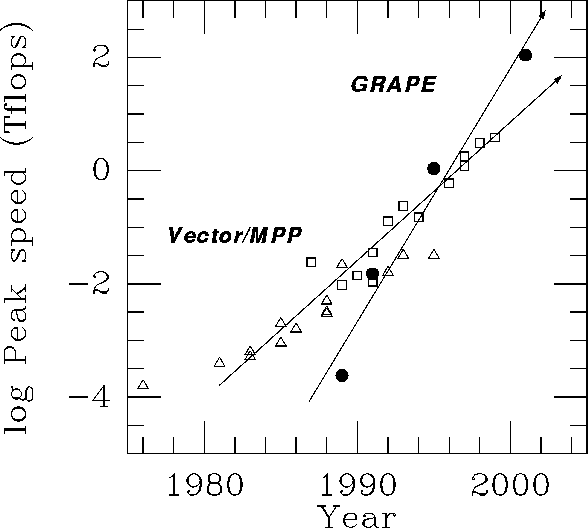
Figure 4: The evolution of GRAPE and general-purpose parallel
computers. The peak speed is plotted against the year of
delivery. Filled circles, open triangles and open squares denote
GRAPEs, vector processors, and parallel processors, respectively.