In 1997, we started the GRAPE-6 project. It's a project funded by JSPS (Japan Society for the Promotion of Science), and planned total budget is about 500 M JYE.
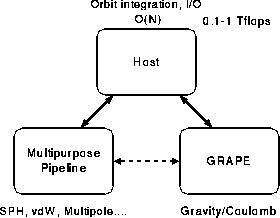
Figure ![]() shows the basic structure of GRAPE-6. The
gravitational pipeline is essentially a scaled-up version of GRAPE-4,
with the peak speed of around 200 Tflops. This part will consist of
around 4000 pipeline chips, each with the peal speed of 50 Gflops. In
comparison, GRAPE-6 consists of 1700 pipeline chips, each with 600
Mflops. The increase of a factor of 100 in speed is achieved by
integrating six pipelines into one chip (GRAPE-4 has one pipeline
which needs three cycles to calculat the force from one particle) and
using 3--4 times higher clock frequency. The advance of the device
technology (from
shows the basic structure of GRAPE-6. The
gravitational pipeline is essentially a scaled-up version of GRAPE-4,
with the peak speed of around 200 Tflops. This part will consist of
around 4000 pipeline chips, each with the peal speed of 50 Gflops. In
comparison, GRAPE-6 consists of 1700 pipeline chips, each with 600
Mflops. The increase of a factor of 100 in speed is achieved by
integrating six pipelines into one chip (GRAPE-4 has one pipeline
which needs three cycles to calculat the force from one particle) and
using 3--4 times higher clock frequency. The advance of the device
technology (from  to
to  ) these
practical.
) these
practical.
The multipurpose pipeline part is a new feature, whose goal is to widen the application range. The original GRAPE architecture consists of only two parts: GRAPE and the host (see figure 1). GRAPE calculates only gravity and everything else is done on the host. This architecture is ideal for pure N-body simulation, but not quite so if we want to deal with, for example, self-gravitating fluid using SPH.
The most costly part of SPH calculation, aside from the gravity, is
the evaluation of the hydrodynamical interaction between
particles. Thus, a specialized pipeline quite similar to that of GRAPE
[YOT 96] could improve the speed quite a lot. However, there
are two reasons to believe it is difficult. The first one is that the
gain one can achieve is limited. Since the interaction
calculation accounts for only around 90% of the total CPU
time, even if the SPH pipeline is infinitely fast the gain we can
achieve does not exceed a factor of 10. The other reason is that there
are many SPH algorithms. Newton's law of the gravity has not
changed in the last two century, and the algorithm to calculate it is
well established. However, SPH is still rather new method. One day
somebody might come up with a novel method, which is much better than
traditional one but cannot be implemented on a specialized
hardware. Thus, it looks rather risky to develop an SPH hardware.
96] could improve the speed quite a lot. However, there
are two reasons to believe it is difficult. The first one is that the
gain one can achieve is limited. Since the interaction
calculation accounts for only around 90% of the total CPU
time, even if the SPH pipeline is infinitely fast the gain we can
achieve does not exceed a factor of 10. The other reason is that there
are many SPH algorithms. Newton's law of the gravity has not
changed in the last two century, and the algorithm to calculate it is
well established. However, SPH is still rather new method. One day
somebody might come up with a novel method, which is much better than
traditional one but cannot be implemented on a specialized
hardware. Thus, it looks rather risky to develop an SPH hardware.
If we can ``program'' the pipeline unit, we can eliminate most of the risks. If someone comes up with a new and improved SPH scheme, a programmable pipeline could still be used for that. Moreover, such a programmable pipeline might be used for many other problems.
One might wander whether a programmable pipeline is a practical concept or not. Didn't the author argued against the programmability in section 3? Well, the advance in the FPGA (field-programmable gate array) technology has made the new approach viable [BA96].
An FPGA can be programmed to realize different functions by loading the configuration data. An FPGA consists of many logic blocks and a switching matrix. A logic block is typically a small lookup table. A SRAM block is used to implement this lookup table so that its function can be changed. The switching matrix can also be programmed to make connections in different ways.
This programmability incurs quite large inefficiency. The circuit size
which can be implemented in the current largest FPGAs is equivalent to
 transistors, while largest LSIs contain more than
transistors, while largest LSIs contain more than  transistors. In addition, there is also speed difference of factor
3--5.
transistors. In addition, there is also speed difference of factor
3--5.
Even with these large overheads, however, FPGAs are now becoming more efficient than general-purpose microprocessors. The reason is quite simple. The efficiency of FPGAs has not been falling too rapidly, since the relative overhead is roughly independent of the technology. In fact, the speed penalty is decreasing, since the signal propagation delay is becoming more important. This delay is not much different for FPGA and usual LSIs.
We have developed a small experimental machine, the PROGRAPE-1
[Hamadaetal1998]. It has two large FPGAs. The FPGA chips in
PROGRAPE-1 can house, for example, one pipeline of GRAPE-3
[OME 93] or WINE-1 [FMI
93] or WINE-1 [FMI 93]. GRAPE-6 will
include a massively-parallel version of this PROGRAPE system, which
can be used for various applications like SPH, Ewald method, and
van-der-Waals force calculation in molecular Dynamics.
93]. GRAPE-6 will
include a massively-parallel version of this PROGRAPE system, which
can be used for various applications like SPH, Ewald method, and
van-der-Waals force calculation in molecular Dynamics.
The GRAPE-6 will be completed by the year 2000. We plan to make small version of GRAPE-6 (peak speed of ``only'' a few teraflops) commercially available by that time. We've found that the commercial availability of small machines is essential to maximize the scientific outcome from GRAPE hardwares.
This work is supported in part by the Research for the Future Program of Japan Society for the Promotion of Science (JSPS-RFTP 97P01102).