The architecture of the high-performance computer showed rather drastic changes in every 10-15 years. In 1960s, single-processor scalar computers such as CDC 6600 were ``supercomputers.'' After the introduction of Cray-1 in 1976, vector processors took over. By around 1990, distributed-memory parallel computers, either based on the CMOS implementation of vector processors (Fujitsu VPP) or on COTS (commodity, off-the-shelf) microprocessors (Cray T3x, ASCI machines, etc.) started to replace vector-parallel computers in some application areas.
These changes were, to a large extent, the results of responses of the computer architects to the advance in the device technology. The advance in the device technology caused miniaturization of the transistors, which resulted in (a) the increase in the available number of transistors and (b) the increase in the switching speed of individual transistors.
Before Cray-1, or its predecessor CDC-7600, the number of transistors available for a computer architect was so small that he could not build a complete parallel multiplier which could deliver one result per clock period. Thus, compared to what the architects have to do now, the design of the high-performance computer at that time was rather simple. First one would design a multi-cycle multiplier which is as large (and therefore fast) as possible within the given budget of transistors, and then add control logics and a memory unit fast enough to keep the multiplier busy. Of course, there are a number of important issues, but the above picture gives the general idea.
As device technology advanced, the available number of transistors increased. At one point, thus, it exceeded the number of transistors needed to implement a fully parallel, single-cycle multiplier. This occurred by late 1960s. Once fully-parallel multiplier had become possible, we could further improve its performance by pipelining.
The natural architecture for fully parallel, pipelined multipliers is the vector processor, with the memory system organized into many independent banks to provide sufficient throughput required by the arithmetic unit. Here, however, the control logic and the memory system became much more complex than those of scalar processors, which meant that a large fraction of the transistors were used for them.
As the device technology advanced further, the available number of
transistors increased even more, and by late 1970s it became
possible to pack multiple vector arithmetic units into a single
computer. Of course, this resulted in the sheer increase in the
complexity of control logics and the memory system. This is simple to
explain. Suppose one arithmetic unit requires n memory banks. If a
computer has p arithmetic units, it needs np memory banks. Since
each arithmetic unit need path to all memory banks, the number of
paths is 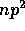 . Thus, at relatively small p most of the transistors
would be consumed by the memory units.
. Thus, at relatively small p most of the transistors
would be consumed by the memory units.
Additional problem with multiple arithmetic units and many memory banks is the wire length. Miniaturization of the transistors resulted in the faster switching speed. However, the speed of light does not change. Therefore, in order to improve the overall speed of a computer, one has to make it smaller and smaller. On the other hand, heat dissipation put the physical limit on the number of transistors per unit volume.
Nonetheless, the device technology advanced further. Here, the only viable solution was to organize large number of transistors to many processors with small number of vector units, and then to connect them with a relatively slow network. This approach is what was first adopted by NAL NWT (Numerical Wind Tunnel of National Aerospace Laboratory of Japan), which was then commercialized as Fujitsu VPP-500. This approach is still being followed by Fujitsu and NEC.
Around the time that Fujitsu VPP-500 arrived, however, a more fundamental transition was underway. High-performance computers illustrated above were implemented mostly in ECL logic. By mid 1990s, however, microprocessors based on CMOS VLSI started to offer the clock speed faster than that of ECL-based vector processors.
Miniaturization benefits both of ECL and CMOS technology, but not in the same way. Because of its comparatively low power consumption, CMOS LSI can house larger number of transistors than ECL LSI. The switching speed of CMOS transistor used to be much slower than that of ECL transistors. By mid 1990s, however, one-chip CMOS microprocessors started to achieve the clock speed comparable or faster than that of ECL-based processors, primarily because of shorter interconnection between transistors. As a result, both Fujitsu and NEC re-implemented their vector processors in CMOS by late 1990s. Both Cray Research and Cray Computer tried to pursue the ECL-like fast logic. The former was merged into SGI and then sold to Tera, and the latter closed the door.
Right now, however, the ``mainstream'' of the high-performance computing is not the parallel vector computers from Fujitsu or NEC, but the clusters of PCs or UNIX servers, sometimes called ``Beowulfs''[2]. They are based on commodity one-chip microprocessors.
This dominance of Beowulfs is the result of the combination of technological and economical developments. At present, it is practically impossible to make a CPU which is faster than these commodity microprocessors, simply because the manufacturers of these ``commodity'' microprocessors actually use the most advanced technology both in the design and manufacturing. This use of the advanced technology was made possible by the sheer number of these processors sold.
However, if we look back the evolution of the microprocessors, we can see that they are now in the same trap as vector processors were in 1980s. Figure 2 shows the maximum number of floating point operations performed per clock cycle for representative microprocessors. The increase in the operation count per cycle was very fast, until it reaches two (one addition and one multiplication ) by 1990. Then the increase stalled, and in 1990s there was essentially no increase. Even in the year 2000, there is no microprocessor which can perform more than four floating point operations per cycle.
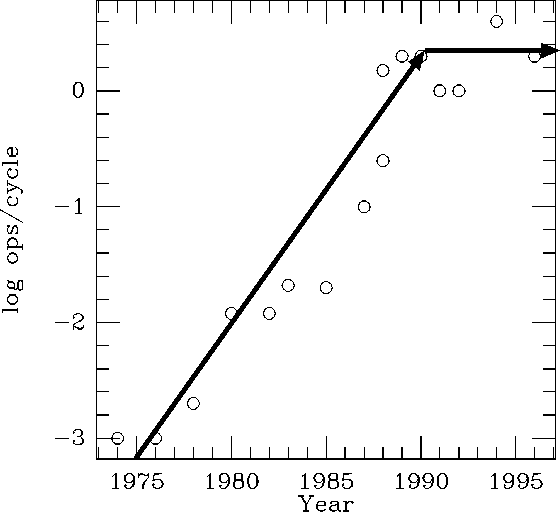
Figure 2: The evolution of the maximum number of floating point
operations performed on representative microprocessors, plotted versus
time. open circles are the values of actual processors. Arrows
indicates the trends.
In other words, practically all the increase in the available number of transistors in 1990s was spent for things other than the arithmetic units. This is exactly the same as what happened to vector processors in 1980s. The only difference is that microprocessors are much cheaper than vector processors. More importantly, their price has been dropping rather fast. Therefore, by hooking up tens of thousands of microprocessors, one can still deliver very impressive peak performance, and that peak performance grows rather nicely as the price drops.
Thus, even though the theoretical peak performance of Beowulfs has been, and will be, increasing, that fact does not imply that they make good use of the device technology. Quite the contrary, they are using ever diminishing fraction of total silicon to do useful floating point operations.
The other problem with the Beowulfs is that their architecture, or rather, non-existence of their architecture, limits their applicability to rather a narrow range of problems. Beowulfs are characterized as bunch of PCs connected via commodity network interface. Thus, the latency and bandwidth of the network interface is relatively low. In addition, usual adoption of TCP/IP based communication software tends to add huge overhead, resulting in a very high latency. One could achieve significantly lower latency and higher throughput by moving to special network hardwares such as Myrinet, but the price becomes much higher as well.
Even with fast networks, it is difficult to reduce the latency of the operations which requires bidirectional communication between the CPU and the network interface. In particular, it's not easy to achieve low latency for global operations, such as global reduction operation.
Finally, the programming model implemented on these clusters, the message-passing model, is the lowest-level libraries to achieve parallel computing, and by no means a high-level, easy-to-use programming environment. Thus, except for very simple problems such as to solve differential equations on a rectangular grid, it is very time-consuming to develop softwares in the message-passing model.
To summarize, the current direction of the evolution of general-purpose high-performance computing (that is, clusters of PCs) has the following problems:
In the next section, we discuss an entirely different approach to large scale scientific computing, namely to build special-purpose computers.