The primary goal of our project is to develop a next-generation massively-parallel computer which is specialized to particle-based simulations, and to make it possible to perform simulations which cannot be handled on general-purpose computers. We also aim to extend the application area of special-purpose computers.
It has been demonstrated that, for particle-based simulations, we can achieve much better cost-performance ratio by developing computing hardware specialized to the evaluation of the interaction between particles. To give just one example, the GRAPE-4 system[MTES97], which we completed in 1995, is the first machine for scientific simulation with the peak speed exceeding one teraflops.
In the present project, we will develop a next-generation special-purpose computer with the peak speed of sub-petaflops range, around one hundred times faster than that of GRAPE-4 system. In addition to this ultra-fast special-purpose computer, we develop a multi-purpose system based on reconfigurable logic. The total system, which we call GRAPE-6, will be a heterogeneous multicomputer which combines these two specialized system with general-purpose parallel computer.
In the following, we briefly discuss the positioning of our GRAPE-6 system compared to general-purpose massively-parallel computers, and why GRAPE-6 system can achieve the high peak speed. As we stated above, the peak speed of GRAPE-6 will be around 100 Tflops, which will be achieved by the final year of the project, FY2001. At that time, the fastest general purpose computer will be the Earth Simulator with the theoretical peak speed of 40 Tflops (design goal of the sustained performance for real application is 5 Tflops), for the total cost of around 400 M USD. The ASCI project in the US has been leading in constructing large machines. In the timeframe of 2001-2002, the biggest ASCI machine will remain to be ASCI Option White with the peak speed of 16 Tflops for the cost of around 100 M USD. The hardware cost of these machines per peak speed in Mflops is around 5--10 USD/Mflops.
The total budget of the present project is around 4.5 M USD. Therefore, for our project goal of 100 Tflops, the cost performance figure is 0.045 USD/Mflops, 100-200 times better than those of general-purpose massively-parallel computers at the same time. In the case of GRAPE-4, the difference was somewhat smaller, around 50 or so.
The reason why there is such a large difference is that the fraction of the silicon real estate used to implement arithmetic logic units is small in the case of general-purpose computer. Moreover, that ratio has been decreasing as silicon semiconductor technology advances. In the 1990s, the number of transistors used in one microprocessors has increased by a factor of 20 or more. However, the number of floating point arithmetic units integrated in a microprocessor has been practically unchanged (see figure 1). In other words, the fraction of the transistors used for arithmetic units has decreased by roughly a factor of 10 in the last decade.

Figure 1: Maximum number of floating point operations per clock cycle for
representative microprocessors
There are many reasons which prevent the increase in the number of arithmetic units per processor, but the most critical one is the limitation in the bandwidth between the processor and the main memory (so-called ``memory wall''). Though we can integrate many arithmetic units, in order to use them efficiently, they need to be connected to the main memory (or at least to the cache memory of some level) with sufficient bandwidth. In the case of the main memory or off-chip cache, this implies we need fast connection between the CPU chip and memory chips. To increase chip-to-chip communication is much harder than to increase the processing power, simply because we cannot increase the number of wires as fast as we can increase the number of transistors. When we reduce the size of transistors by a factor of two, we can use four times more transistors. However, for off-chip connection, or even for on-chip connections, we can increase the number of wires only by a factor of two. In practice, it's harder to increase the off-chip wire density to match with on-chip wire density. Also, we cannot really scale the on-chip wire size, unless all the wires are short. For long wires, RC delay can easily become much larger than the switching delay of transistors, with the present and future deep submicron technology.
The advantage of the specialize architecture such as GRAPE is that we
can use almost all transistors available on chip to implement
arithmetic units. As a result, we can achieve the performance orders
of magnitudes higher than what is possible with general-purpose
processors. In the case of GRAPE hardwares, the nature of the target
physical system allows such efficient use of transistors. The target
system consists of many particles interacting with long-range
forces. Thus, the amount of computation is 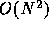 , while the amount
of data is
, while the amount
of data is 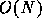 , where N is the number of particles in the
system. By designing an architecture which makes good use of this
characteristics of the target system, we can use large number of
transistors made available by state-of-the-arts semiconductor
technology. Thus, as long as there is no drastic change in the
way general-purpose computers are designed, the relative advantage of
special-purpose computers such as GRAPE over general-purpose computer
will keep increasing in the future.
, where N is the number of particles in the
system. By designing an architecture which makes good use of this
characteristics of the target system, we can use large number of
transistors made available by state-of-the-arts semiconductor
technology. Thus, as long as there is no drastic change in the
way general-purpose computers are designed, the relative advantage of
special-purpose computers such as GRAPE over general-purpose computer
will keep increasing in the future.
To summarize, we believe the importance of the special-purpose computing in the research in computational science and engineering will increase in the future, primarily because the relative advantage of special-purpose approach over general-purpose approach will increase. One of the main goals of the present project is to demonstrate the relative advantage of special-purpose computers.
The second goal of our project is to construct a multi-purpose system for particle-based simulations using reconfigurable logic chips (FPGA; Field-Programmable Gate Arrays). An FPGA chip is essentially an logic LSI chip whose internal circuit design can be reprogrammed after production of the physical chip. Such a programmability is realized by a combination of logic elements by table-lookup and interconnection with programmable switches. Typically, configuration of these lookup tables and switches are stored in SRAMs, and can be downloaded while the system is in operation (while the power is up).
The use of FPGA chip as the pipeline chip for GRAPE-like system has several important advantages compared to the use of full-custom LSI chips. The most important one is the low initial development cost. The development cost of current state-of-the-arts custom logic chips exceeds 1 million USD (as of 1997-1998). On the other hand, we can buy FPGA chips which are mass-produced for less than 1,000 USD (large FPGA chips are, however, expensive, exceeding 3,000 USD per chip). The programmability also implies a shorter design cycle, since we can correct the mistake in the logic design just by changing the data to be downloaded to the FPGA chips. Thus the debugging cycle is much less than a day. The change in the hardware design of a custom chip would take at least a few months and lots of money.
The disadvantage of FPGA chips compared to full-custom design is that they offer much less number of gates which are much slower. Thus, the advantage of FPGA chips is the flexibility, while the disadvantage is the performance. Very roughly, we can position machines based on FPGA chips between general-purpose computers and fully specialized computers such as a GRAPE for gravity.
There have been numerous projects to use FPGAs for high-performance computing. One of the pioneers, and probably most well known, is Splash [BA96]. So far, these projects have been successful only in rather limited application area such as the sequence matching for DNA. The primary reason for this limited success is that FPGAs have not been large enough to implement floating-point arithmetic units with standard 64- or even 32-bit precision. In fact, the FPGA chips which will be available in the near future will not be large and fast enough that we can implement pipeline logic such as what we use for gravity processor in our project.
In our project, we will use FPGA chips to implement the short-range particle-particle interactions which are less costly than the long-range interactions such as gravity or Coulomb interactions. There are a number of applications where such short-range interactions are important. One example is the classical molecular dynamics, where particles (atoms) interact with others through bonding force (chemical bonds), non-bonding short-range forces (van der Waals force) and long-range force (Coulomb force).
Other examples include smoothed particle hydrodynamics (SPH), element-free Galerkin method and other ``gridless'' methods to handle continuous systems. In these methods, partial differential equations are discretized through distribution and interaction of particles. This approach allows us to achieve adaptivity and parallelization relatively easily, compared to traditional finite-difference or finite-element methods based on regular or irregular grids. On the other hand, the gridless nature of these methods implies inherently higher calculation cost compared to grid-based methods. The reconfigurable computer for particle-based simulation would offer a cost-effective solution for these methods.