We first develop a massively-parallel special-purpose system for gravity and Coulomb interaction. The peak speed of this part will be around 100 Tflops. For this system, we will develop a custom LSI processor chip. At the same time, we will develop a reconfigurable multi-purpose machine with the overall architecture specialized for the evaluation of particle-particle interaction, but using reconfigurable FPGA chips as the processing element. The speed of this reconfigurable system will depend strongly on the type of applications, but for typical applications with relatively low accuracy requirement it would offer around 1 Tflops. The total system will connect these two specialized systems with general-purpose frontend (Figure 2). We will apply this machine to astrophysical N-body simulations, classical MD (molecular dynamics) simulations, and other applications such as particle-based hydrodynamical simulations such as SPH.
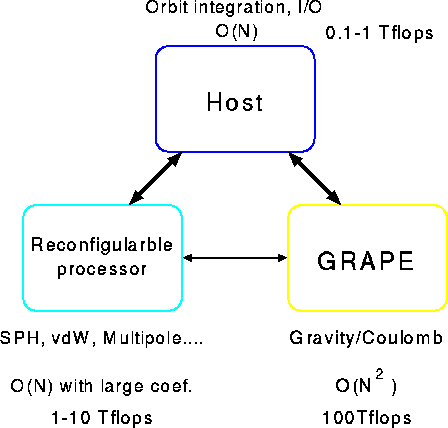
Figure 2: The architecture of the whole system
In the following, we give a brief overview of the gravity/Coulomb processor and reconfigurable multi-purpose system.
The current goal of the peak speed of the gravity/Coulomb processor is
100 Tflops. In order to achieve this performance, we will use
around 3,000 processor chips with the peak speed of around 33 Gflops
each. The processor chip is manufactured by 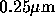 process
and integrates six pipeline processors for gravity/Coulomb interaction
on chip. It operates at the clock speed of around 92 MHz, and achieved
the peak speed of 31 Gflops.
process
and integrates six pipeline processors for gravity/Coulomb interaction
on chip. It operates at the clock speed of around 92 MHz, and achieved
the peak speed of 31 Gflops.
These 3,000 processor chips are organized as follows. First, four chips with their local memories are mounted on what we call ``processor modules'', with the size of 130 mm by 90 mm (figure 3).

Figure 3: The top (left) and bottom (right) views of the GRAPE-6
processor modules. Four large chips on the top side are the processor
chips. Eight chips on the bottom side are memory chips.
Eight of these processor modules are then mounted to the processor board shown in the left panel of figure 4. Eight of these processor boards are connected to the host computer through a two-stage tree network made of three network boards shown in the right panel of figure 4.

Figure 4: Processor board (left) and Network board (right).
These boards are housed in a card cage shown in figure 5. We plan to build 12 to 16 racks in total, depending on the budget we will be awarded in FY2001.

Figure 5: A card cage with four processor boards installed.
For this part, it is difficult to specify a definite goal for the peak speed, since the performance varies depending on the applications, in particular the required accuracy. For the multi-purpose reconfigurable processor we will develop in our project, we place the following goals:
When we require standard 32-bit floating-point accuracy, the speed of one chip will be around 1 Gflops, and that of the total system 1 Tflops. This is the worst case performance and if the required accuracy is lower we can achieve much higher performance.